
der Kontext ist wirklich alles. Die Qualität der Ergebnisse eines LLM hängt eng mit der Qualität und Menge der von Ihnen bereitgestellten Informationen zusammen. In der Praxis sind viele reale Anwendungsfälle mit massiven Kontexten verbunden: Codegenerierung über große Codebasen, Abfragen komplexer Wissenssysteme oder sogar lange, mäandrierende Chats bei der Suche nach dem perfekten Urlaubsziel (das haben wir alle schon erlebt).
Leider können LLMs nur mit einer begrenzten Menge an Kontext effizient arbeiten. Dabei geht es nicht nur um die harten Grenzen des Kontextfensters, insbesondere jetzt, da Grenzmodelle Hunderttausende oder sogar Millionen von Token unterstützen. Und diese Grenzen wachsen immer weiter. Die größere Herausforderung ist ein Phänomen namens Kontextfäulewobei die Modellleistung mit zunehmender Kontextlänge abnimmt.
Dieser Effekt wird in dem Artikel „RULER: What’s the Real Context Size of Your Long-Context Language Models?“ deutlich demonstriert. von Hsieh et al. Die Autoren stellen RULER vor, einen neuen Benchmark zur Bewertung der Langkontextleistung, und testen eine Reihe von Modellen. Die Ergebnisse zeigen ein konsistentes Muster: Mit zunehmender Kontextlänge sinkt die Leistung bei allen Modellen erheblich. In vielen Fällen beträgt die effektive Kontextlänge (wobei die Leistung mit Llama 2–7B vergleichbar bleibt) nur etwa 50 % des angekündigten Kontextfensters oder sogar weniger.
In ihrem jüngsten Artikel „Rekursive Sprachmodelle“, Zhang et al. Schlagen Sie einen vielversprechenden Ansatz zur Lösung des Kontextfäuleproblems vor. In diesem Artikel möchte ich mir diese Idee genauer ansehen und untersuchen, wie sie in der Praxis funktioniert, indem ich die kürzlich hinzugefügte Unterstützung von DSPy für diese Inferenzstrategie nutze.
Rekursive Sprachmodelle
Rekursive Sprachmodelle (RLMs) wurden eingeführt, um Leistungseinbußen bei zunehmender Kontextlänge entgegenzuwirken und es LLMs zu ermöglichen, mit sehr großen Kontexten zu arbeiten (bis zu zwei Größenordnungen über das native Kontextfenster des Modells hinaus). Dies wird immer wichtiger, da wir LLMs für Aufgaben einsetzen, bei denen Hunderte Millionen Token verarbeitet werden.
Für die Bewältigung langfristiger Aufgaben gibt es bereits mehrere Ansätze. Das häufigste Problem (etwas, das Ihnen wahrscheinlich bei der Verwendung von Code-Agenten wie Cursor begegnet ist) ist Kontextzusammenfassung. In diesem Setup wird der Gesprächs- oder Arbeitskontext wiederholt zusammengefasst, sobald er sich der Kontextgrenze des Modells nähert. In der Praxis greift dies jedoch oft zu kurz: Wichtige Details und subtile Nuancen aus früheren Schritten gehen tendenziell verloren, da das Modell alte Informationen „vergisst“, um Platz für neue Token zu schaffen.
Rekursive Sprachmodelle verfolgen einen anderen und überraschend eleganten Ansatz. Anstatt jedes Mal die gesamte Eingabeaufforderung an das LLM zu übergeben, wird die Eingabeaufforderung als eine Reihe von Variablen behandelt, die in einer Python-REPL-Umgebung (Read-Eval-Print-Loop) verfügbar sind. Das Modell ist mit Werkzeugen ausgestattet, die es ihm ermöglichen, diese Variablen zu überprüfen oder sich selbst rekursiv auf programmgesteuert ausgewählten Fragmenten aufzurufen.

Mit anderen Worten: RLMs ermutigen das LLM, Code zu schreiben, der seine eigenen Unteraufgaben erstellt, und diese Unteraufgaben dann zu lösen, indem es sich selbst rekursiv aufruft. Dadurch verlagert sich die Last von der Aufgabe, alles in einer einzigen Eingabeaufforderung zusammenzufassen, hin zur Strukturierung des Problems, sodass das Modell zuverlässiger in großen Kontexten navigieren kann.
Die Autoren bewerteten ihren Ansatz anhand mehrerer Langzeitaufgaben, bei denen RLMs sowohl bei GPT-5- als auch bei Qwen-3-Modellen starke Ergebnisse lieferten.
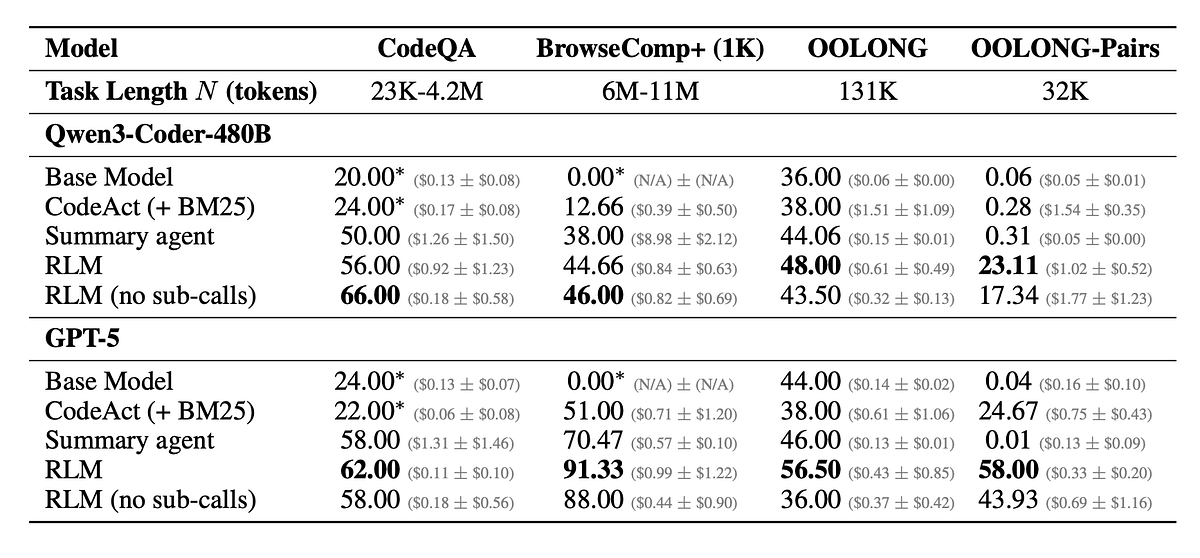
Die Ergebnisse sehen äußerst vielversprechend aus. RLMs (mit oder ohne Unteraufrufe) übertreffen andere Ansätze bei allen Aufgaben durchweg. Mal sehen, wie das in der Praxis funktioniert.
RLM in der Praxis nutzen
Ein häufiges Szenario, in dem ein langer Kontext besonders gut zur Geltung kommt, ist die Beantwortung von Fragen in einer großen Wissensdatenbank. Genau das werden wir hier versuchen. Ich habe alle Artikel, die ich auf Towards Data Science veröffentlicht habe, in eine einzige Markdown-Datei geladen. Überraschenderweise summiert sich das auf fast 1,5 MB Text. Hoffentlich reicht das für das Modell aus.
Glücklicherweise hat DSPy kürzlich eine Implementierung des Inferenzansatzes rekursiver Sprachmodelle eingeführt. Das bedeutet, dass wir nichts selbst bauen müssen; wir benötigen lediglich DSPy Version 3.1.2 oder neuer.
pip install dspy --upgradeBeginnen wir mit dem Laden des Datensatzes.
with open('articles.md', 'r') as f:
articles = f.read()Als nächstes überprüfen wir, wie viele Token darin enthalten sind.
import anthropic
client = anthropic.Anthropic(api_key=config('ANTHROPIC_API_KEY'))
# Count tokens for messages
token_count = client.messages.count_tokens(
model="claude-sonnet-4-5",
messages=(
{"role": "user", "content": articles}
)
)
print(f"Input tokens: {token_count.input_tokens}")
# Input tokens: 386768In unserem Kontext gibt es fast 400.000 Token. Claude Sonnet 4.5 unterstützt ein 200-KByte-Kontextfenster, sodass die Verarbeitung des gesamten Datensatzes in einer einzigen Eingabeaufforderung nicht möglich ist. Genau hier kommt RLM zum Einsatz.
Um DSPy verwenden zu können, müssen wir zunächst das Sprachmodell konfigurieren. Wie bereits erwähnt, ist RLM für die Interaktion mit der Eingabeaufforderung auf Code angewiesen und funktioniert daher am besten mit Modellen, die über starke Codierungsfunktionen verfügen. Aus diesem Grund verwende ich in diesem Beispiel Claude, da es bekanntermaßen eine gute Leistung bei Code-bezogenen Aufgaben erbringt.
lm = dspy.LM('anthropic/claude-sonnet-4-5', api_key=config('ANTHROPIC_API_KEY'))
dspy.configure(lm=lm)Als nächstes initialisieren wir das RLM, indem wir seine Signatur angeben. In diesem Anwendungsfall übergebe ich den gesamten Artikelsatz zusammen mit einer Frage und erwarte, dass das Modell wichtige Trends extrahiert und sie als Liste von Zeichenfolgen zurückgibt.
rlm = dspy.RLM('articles, question -> trends: list(str)')Hier verwende ich Claude Sonnet 4.5 sowohl für das Hauptmodell als auch für die rekursiven Unteraufrufe. Mit DSPy können Sie auch ein kleineres Modell für Unteranrufe über verwenden
sub_lmParameter, der zur Kostensenkung beitragen kann.
Jetzt können wir das RLM ausführen und darauf zugreifen trends Feld in der Ausgabe.
output = rlm(
articles = articles,
question = '''What were the main AI trends of 2025 based on provided
articles? Pay attention to the content not only the titles.'''
)
print('n'.join(output.trends))
# Agentic AI and Autonomous Systems: Self-reflection patterns, iterative improvement through feedback loops (Self-Refine, Reflexion, CRITIC), and LLMs as reasoning engines that can autonomously plan and execute tasks
# Multi-Agent AI Systems: Evolution from single agents to collaborative teams of specialized agents with distinct roles, using frameworks like LangGraph, CrewAI, and AutoGen for orchestration
# Context Engineering and RAG: Moving beyond static prompting to dynamic retrieval-augmented generation (RAG), adaptive memory systems, and self-improving contexts that learn from experience without retraining
# Standardization Protocols: Emergence of Model Context Protocol (MCP) for standardizing LLM-tool integrations and Agent Communication Protocol (ACP) for inter-agent communication, reducing integration complexity
# Tool-Using LLMs and Function Calling: LLMs equipped with ability to invoke external tools, execute SQL queries, browse web, and interact with APIs through structured function calling mechanisms
# Production-Ready AI Frameworks: Mature ecosystem including LangGraph, DSPy, LangChain, NeMo Agent Toolkit, CrewAI, and AutoGen, focused on moving from prototype to production with built-in observability
# LLM Evaluation and Observability: LLM-as-judge evaluation patterns, comprehensive metrics frameworks (Ragas, DeepEval, Evidently), trajectory evaluation, and continuous monitoring as essential production infrastructure
# Programming Over Prompting: Shift toward declarative, code-based AI development with frameworks like DSPy and configuration-driven approaches (YAML-based) replacing prompt engineering
# Framework Interoperability: Tools designed to integrate across multiple frameworks rather than create silos, enabling composable AI architectures that leverage best features from different ecosystems
# Local and Cost-Effective LLM Deployment: Running smaller efficient models locally (Llama, Ollama) to reduce API costs and enable experimentation, with focus on cost-quality-latency tradeoffs
# SQL Agents and Data Analysis Automation: LLM agents specialized in data analysis tasks, generating and executing SQL queries, with applications in replacing or augmenting traditional data analyst workflows
# Production Quality and Accuracy Enhancement: Techniques for improving LLM accuracy including chain-of-thought reasoning, structured outputs through function calling, and iterative refinement for business-critical applicationsDie Ausführung dauerte etwa drei Minuten und das Ergebnis war eine überraschend plausible Zusammenfassung der Hauptthemen meiner Artikel. Wir sind jedoch nicht hier, um etwas über die Trends selbst zu erfahren. Die interessantere Frage ist, wie RLM dies überhaupt geschafft hat. Also lasst uns tiefer graben.
RLM unter der Haube
Das Faszinierendste ist natürlich, zu verstehen, was tatsächlich unter der Haube passiert.
RLM-Implementierung
Wie bereits erwähnt, besteht die Schlüsselidee hinter rekursiven Sprachmodellen darin, dass lange Kontexte als Teil einer externen Umgebung behandelt werden und nicht als einzelne Eingabeaufforderung direkt in das Modell eingespeist werden. Stattdessen schreibt das LLM Python-Code, um Unter-LLMs über kleinere Datenausschnitte programmgesteuert zu prüfen, zu zerlegen und rekursiv aufzurufen.
Auf hoher Ebene weist die Implementierung einige Kernmerkmale auf:
- Es verwendet eine Sandbox-Python-REPL (Read-Eval-Print-Schleife), die es dem LLM ermöglicht, große Kontexte durch Codeausführung zu erkunden.
- Das LLM arbeitet in einer bekannten Agentenschleife: Es schreibt Python-Code, beobachtet die Ausgabe und entscheidet dann, was als nächstes zu tun ist.
- Es kann mit Tools wie rekursive Unteraufrufe ausführen (also sich selbst aufrufen).
llm_query()Undllm_query_batched()um kleinere Blöcke semantisch zu analysieren. - Sobald das Modell mit dem Ergebnis zufrieden ist, schließt es den Prozess durch einen Aufruf ab
SUBMIT()mit der Ausgabe.
Aufforderungen
Um wirklich zu verstehen, wie das funktioniert, finde ich es hilfreich, die tatsächlichen Nachrichten zu untersuchen, die an und von der LLM gesendet werden. DSPy macht dies mit dem folgenden Befehl einfach.
# Inspect the raw LLM calls - shows the actual prompts sent to the model
dspy.inspect_history(n=39)Dies gibt uns einen vollständigen Einblick in das, was bei jedem Schritt mit dem Modell geteilt wurde.
Beginnen wir mit der Systemmeldung. Es definiert die für das Modell verfügbaren Eingabevariablen (wie in der RLM-Signatur angegeben) und listet die Funktionen auf, die das Modell aufrufen kann, z printrekursive LLM-Aufrufe und Standardbibliotheksdienstprogramme.
Insbesondere können Sie mit dem RLM-Modul auch benutzerdefinierte Funktionen für die Python REPL verfügbar machen
toolsParameter bei der Initialisierung des RLM. In diesem Beispiel habe ich mich nur auf die Standardfunktionen verlassen, aber in fortgeschritteneren Setups kann dies ein leistungsstarker Erweiterungspunkt sein.
Your input fields are:
1. `variables_info` (str): Metadata about the variables available in the REPL
2. `repl_history` (REPLHistory): Previous REPL code executions and their outputs
3. `iteration` (str): Current iteration number (1-indexed) out of max_iterations
Your output fields are:
1. `reasoning` (str): Think step-by-step: what do you know? What remains? Plan your next action.
2. `code` (str): Python code to execute.
All interactions will be structured in the following way, with the appropriate values filled in.
(( ## variables_info ## ))
{variables_info}
(( ## repl_history ## ))
{repl_history}
(( ## iteration ## ))
{iteration}
(( ## reasoning ## ))
{reasoning}
(( ## code ## ))
{code}
(( ## completed ## ))
In adhering to this structure, your objective is:
Given the fields `articles`, `question`, produce the fields `trends`.
You are tasked with producing the following outputs given the inputs `articles`, `question`:
- {trends} # note: the value you produce must adhere to the JSON schema: {"type": "array", "items": {"type": "string"}}
You have access to a Python REPL environment. Write Python code and it will be executed. You will see the output, then write more code based on what you learned. This is an iterative process.
Available:
- Variables: `articles`, `question` (your input data)
- `llm_query(prompt)` - query a sub-LLM (~500K char capacity) for semantic analysis
- `llm_query_batched(prompts)` - query multiple prompts concurrently (much faster for multiple queries)
- `print()` - ALWAYS print to see results
- `SUBMIT(trends)` - submit final output when done
- Standard libraries: re, json, collections, math, etc.
IMPORTANT: This is ITERATIVE. Each code block you write will execute, you'll see the output, then you decide what to do next. Do NOT try to solve everything in one step.
1. EXPLORE FIRST - Look at your data before processing it. Print samples, check types/lengths, understand the structure.
2. ITERATE - Write small code snippets, observe outputs, then decide next steps. State persists between iterations.
3. VERIFY BEFORE SUBMITTING - If results seem wrong (zeros, empty, unexpected), reconsider your approach.
4. USE llm_query FOR SEMANTICS - String matching finds WHERE things are; llm_query understands WHAT things mean.
5. MINIMIZE RETYPING (INPUTS & OUTPUTS) - When values are long, precise, or error-prone (IDs, numbers, code, quotes), re-access them via variables and parse/compute in code instead of retyping. Use small, targeted prints to sanity-check, but avoid manual copying when variables can carry the exact value.
6. SUBMIT ONLY AFTER SEEING OUTPUTS - SUBMIT ends the current run immediately. If you need to inspect printed output, run it in one step, review the result, then call SUBMIT in a later step.
You have max 50 sub-LLM calls. When done, call SUBMIT() with your output.Schauen wir uns auch die erste Benutzernachricht an, die an das LLM gesendet wurde. Dadurch erhält das Modell einen Überblick über die Eingabevariablen: deren Typen, Längen (damit das Modell weiß, wie viel es auf einmal lesen kann) und eine Vorschau des Inhalts, um die Struktur zu verstehen.
(( ## variables_info ## ))
(1) «««
Variable: `articles` (access it in your code)
Type: str
Total length: 1,392,921 characters
Preview:
```
---
title: "Agentic AI from First Principles: Reflection"
date: "2025-10-24T12:00:00-05:00"
category: "Agentic AI"
read_time: "21 min read"
url: "https://towardsdatascience.com/agentic-ai-from-first-principles-reflection/"
---
Arthur C. Clarke's Third Law says that "*any sufficiently advanced technology is indistinguishable from magic*". That's exactly how a lot of today's AI frameworks feel. Tools like GitHub Copilot, Claude Desktop, OpenAI Operator, and Perplexity Comet are automating everyda...
```
»»»
(2) «««
Variable: `question` (access it in your code)
Type: str
Total length: 114 characters
Preview:
```
What were the main AI trends of 2025 based on provided articles? Pay attention to the content not only the titles.
```
»»»
(3) «««
Variable: `verbose` (access it in your code)
Type: bool
Total length: 4 characters
Preview:
```
True
```
»»»
(( ## repl_history ## ))
You have not interacted with the REPL environment yet.
(( ## iteration ## ))
1/20
Respond with the corresponding output fields, starting with the field `(( ## reasoning ## ))`, then `(( ## code ## ))`, and then ending with the marker for `(( ## completed ## ))`.Hier ist die erste Antwort des Modells entsprechend dem in der Benutzernachricht angegebenen Format.
(( ## reasoning ## ))
I need to analyze articles to identify main AI trends of 2025. Let me start by exploring the data:
1. First, I'll examine the structure and content of the `articles` variable to understand what I'm working with
2. I'll need to look at multiple articles, not just titles, to understand the actual content
3. Then I'll use semantic analysis (llm_query) to extract and identify trends
4. Finally, I'll compile the trends into a list
Let me start by exploring the articles data to see its structure and get a sense of what's available.
(( ## code ## ))
# First, let's understand the structure of the articles
print("Type of articles:", type(articles))
print("nLength of articles:", len(articles))
print("n" + "="*80)
print("First 2000 characters:")
print(articles(:2000))
print("n" + "="*80)
# Let's see if we can identify the structure - looks like articles are separated
# Let's try to split and count them
article_separator = "---ntitle:"
article_parts = articles.split(article_separator)
print(f"nNumber of article parts found: {len(article_parts)}")
print(f"First part length: {len(article_parts(0))} (likely empty or header)")
print(f"Second part length: {len(article_parts(1)) if len(article_parts) > 1 else 0}")
(( ## completed ## ))Die Rohprotokolle gaben uns ein solides Verständnis dafür, wie das LLM mit der Umgebung unter der Haube interagiert. Als nächstes untersuchen wir die Flugbahn, die das LLM verfolgte, um seine endgültige Ausgabe zu erreichen.
Flugbahn
Für eine strukturierte Sicht auf die Flugbahn können wir inspizieren output.trajectory. Dies ermöglicht den Zugriff auf jeden Schritt der Modellbegründung, den von ihm generierten Code und die resultierenden Ausgaben. Im Wesentlichen bietet es einen umfassenden Überblick über alle REPL-Interaktionen.
# Examine the full trajectory - this shows all REPL interactions
for i, step in enumerate(output.trajectory):
print(f"n{'='*60}")
print(f"STEP {i+1}")
print(f"{'='*60}")
print(f"n📝 REASONING:n{step('reasoning')}")
print(f"n💻 CODE:n{step('code')}")
print(f"n📤 OUTPUT:n{step('output')(:1000)}{'...' if len(step('output')) > 1000 else ''}")Das vollständige Protokoll finden Sie auch auf GitHub.
Die Überprüfung der Flugbahn hilft uns, die Hauptmuster zu verstehen, die das LLM zur Lösung des Problems verwendet. In diesem Fall waren 13 Schritte erforderlich, um zur endgültigen Antwort zu gelangen.
Der erste Schritt bestand erwartungsgemäß darin, das zu erkunden articles Variable: Untersuchung ihrer Struktur und Gewinnung eines Gefühls für die verfügbaren Daten. Diese erste Erkundung bildet die Grundlage für alle nachfolgenden Überlegungen und Unteraufrufe.
# First, let's understand the structure of the articles
print("Type of articles:", type(articles))
print("nLength of articles:", len(articles))
print("n" + "="*80)
print("First 2000 characters:")
print(articles(:2000))
print("n" + "="*80)
# Let's see if we can identify the structure - looks like articles are separated
# Let's try to split and count them
article_separator = "---ntitle:"
article_parts = articles.split(article_separator)
print(f"nNumber of article parts found: {len(article_parts)}")
print(f"First part length: {len(article_parts(0))} (likely empty or header)")
print(f"Second part length: {len(article_parts(1)) if len(article_parts) > 1 else 0}")Als nächstes stellte das LLM fest, dass es insgesamt 40 Artikel gab, die jeweils durch getrennt waren ---ntitle:und dass jeder Artikel Metadatenfelder wie enthielt title, date, category, read_timeUnd urlgefolgt vom Hauptinhalt. Allein die Identifizierung dieser Struktur anhand einer 1,5 MB großen Textdatei ist bereits eine bedeutende Leistung.
Aufbauend auf diesem Verständnis analysierte das LLM dann die Artikel und erstellte eine Zusammenfassung der Artikeltitel und Hauptthemen.
# Parse articles into structured format
import re
# Split by the article separator
raw_articles = articles.split("---ntitle:")
# Process each article (skip the first empty element)
parsed_articles = ()
for i, raw_article in enumerate(raw_articles(1:), 1): # Skip first empty element
# Add back the "title:" that was removed by split
raw_article = "title:" + raw_article
# Extract metadata using regex
title_match = re.search(r'title:s*"((^")*)"', raw_article)
date_match = re.search(r'date:s*"((^")*)"', raw_article)
category_match = re.search(r'category:s*"((^")*)"', raw_article)
# Find where content starts (after the second "---")
content_start = raw_article.find("---", 10) # Skip the first part
content = raw_article(content_start+3:).strip() if content_start != -1 else ""
parsed_articles.append({
'index': i,
'title': title_match.group(1) if title_match else "Unknown",
'date': date_match.group(1) if date_match else "Unknown",
'category': category_match.group(1) if category_match else "Unknown",
'content': content,
'content_length': len(content)
})
print(f"Successfully parsed {len(parsed_articles)} articlesn")
print("="*80)
print("Sample of articles (titles and categories):")
print("="*80)
for i, article in enumerate(parsed_articles(:10), 1):
print(f"{i}. ({article('category')}) {article('title')}")
print(f" Content length: {article('content_length')} chars")
print()Nach der Analyse der Artikel entschied sich das LLM, sich ausschließlich auf KI-bezogene Inhalte zu konzentrieren, da es sich bei der Frage speziell um KI-Trends handelte.
# Let's focus on AI-related articles (AI, Agentic AI, LLM Applications, ChatGPT categories)
# and sample strategically to understand content-based trends
ai_related = (a for a in parsed_articles if a('category') in (
'Artificial Intelligence', 'Agentic AI', 'LLM Applications', 'ChatGPT', 'Deep Learning'
))Als nächstes identifizierte das LLM die Schlüsselartikel, auf die es sich konzentrieren wollte. Es handelte sich um eine subjektive Auswahl nach Relevanz und Inhalt. Um diese im Detail zu analysieren, wurden rekursive Unteraufrufe verwendet, wobei jeder Artikel programmgesteuert verarbeitet wurde.
Um die Arbeitsbelastung effizient zu bewältigen, teilte das LLM die Artikel in zwei Chargen auf und verarbeitete sie nacheinander. Für jeden Artikel wurde außerdem der Inhalt auf die ersten 15.000 Zeichen gekürzt. Diese Strategie ermöglichte es dem Modell, eine große Textmenge zu verarbeiten, ohne sein Kontextfenster zu überschreiten, und gleichzeitig die wichtigsten Erkenntnisse aus jedem Artikel zu erfassen.
# Create prompts to extract AI trends from article content
# I'll include a substantial portion of each article's content for analysis
prompts_batch1 = ()
for i, article in enumerate(selected_for_analysis(:8)): # First batch of 8
# Take first ~15K chars of content to stay within LLM limits while getting substance
content_sample = article('content')(:15000)
prompt = f"""Analyze this article about AI from 2025 and identify the main AI trends, technologies, methodologies, or concepts it discusses.
Article Title: {article('title')}
Article Content (excerpt):
{content_sample}
Based on the content above, list the key AI trends, technologies, or concepts discussed in this article. Focus on:
- New frameworks, tools, or methodologies mentioned
- Emerging patterns in AI development (e.g., agentic AI, multi-agent systems)
- Important techniques or approaches
- Production/deployment considerations
Provide a concise list of 3-5 main trends/concepts from this article."""
prompts_batch1.append(prompt)
print(f"Created {len(prompts_batch1)} prompts for first batch")
print("nProcessing first batch of articles...")
# Query the first batch
results_batch1 = llm_query_batched(prompts_batch1)
print(f"nReceived {len(results_batch1)} results")
print("nResults from first batch:")
print("="*80)
for i, (article, result) in enumerate(zip(selected_for_analysis(:8), results_batch1), 1):
print(f"n{i}. {article('title')}")
print("-"*80)
print(result)
print()Abschließend überprüfte das LLM noch einmal die vollständige Liste der Artikel, identifizierte weitere relevante Themen und verarbeitete diese mithilfe rekursiver Unteraufrufe auf die gleiche Weise. Nachdem alle Informationen abgerufen worden waren, wurden die Ergebnisse zusammengefasst trends_2025 Variable (eine Liste von Zeichenfolgen, die die wichtigsten KI-Trends darstellen) und übermittelte sie als endgültige Antwort.
##### STEP 12 #####
# Now let me synthesize all findings into comprehensive AI trends
# I'll review all the results and create a structured summary
print("SYNTHESIZING ALL FINDINGS FROM 20 ANALYZED ARTICLES")
print("="*80)
print("nBased on deep content analysis of 20 AI-focused articles from 2025,")
print("here are the main AI trends identified:n")
# Compile the comprehensive list of trends
trends_2025 = (
"Agentic AI and Autonomous Systems: Self-reflection patterns, iterative improvement through feedback loops (Self-Refine, Reflexion, CRITIC), and LLMs as reasoning engines that can autonomously plan and execute tasks",
"Multi-Agent AI Systems: Evolution from single agents to collaborative teams of specialized agents with distinct roles, using frameworks like LangGraph, CrewAI, and AutoGen for orchestration",
"Context Engineering and RAG: Moving beyond static prompting to dynamic retrieval-augmented generation (RAG), adaptive memory systems, and self-improving contexts that learn from experience without retraining",
"Standardization Protocols: Emergence of Model Context Protocol (MCP) for standardizing LLM-tool integrations and Agent Communication Protocol (ACP) for inter-agent communication, reducing integration complexity",
"Tool-Using LLMs and Function Calling: LLMs equipped with ability to invoke external tools, execute SQL queries, browse web, and interact with APIs through structured function calling mechanisms",
"Production-Ready AI Frameworks: Mature ecosystem including LangGraph, DSPy, LangChain, NeMo Agent Toolkit, CrewAI, and AutoGen, focused on moving from prototype to production with built-in observability",
"LLM Evaluation and Observability: LLM-as-judge evaluation patterns, comprehensive metrics frameworks (Ragas, DeepEval, Evidently), trajectory evaluation, and continuous monitoring as essential production infrastructure",
"Programming Over Prompting: Shift toward declarative, code-based AI development with frameworks like DSPy and configuration-driven approaches (YAML-based) replacing prompt engineering",
"Framework Interoperability: Tools designed to integrate across multiple frameworks rather than create silos, enabling composable AI architectures that leverage best features from different ecosystems",
"Local and Cost-Effective LLM Deployment: Running smaller efficient models locally (Llama, Ollama) to reduce API costs and enable experimentation, with focus on cost-quality-latency tradeoffs",
"SQL Agents and Data Analysis Automation: LLM agents specialized in data analysis tasks, generating and executing SQL queries, with applications in replacing or augmenting traditional data analyst workflows",
"Production Quality and Accuracy Enhancement: Techniques for improving LLM accuracy including chain-of-thought reasoning, structured outputs through function calling, and iterative refinement for business-critical applications"
)
print("MAIN AI TRENDS OF 2025:")
print("="*80)
for i, trend in enumerate(trends_2025, 1):
print(f"n{i}. {trend}")
print("n" + "="*80)
print(f"nTotal trends identified: {len(trends_2025)}")
print("nThese trends are based on content analysis of articles covering:")
print("- Agentic AI systems and design patterns")
print("- Multi-agent architectures and frameworks")
print("- Production deployment and evaluation")
print("- Emerging protocols and standardization")
print("- Tool use and external system integration")
print("- Cost-effective and accurate LLM applications")
##### STEP 13 #####
# Submit the final list of AI trends from 2025
SUBMIT(trends_2025)Wir können sehen, dass das Modell ziemlich kreativ war: Es verstand die Struktur unseres Inhalts, analysierte die Artikel und verwendete rekursive Aufrufe, um jeden einzelnen Artikel einzeln zu verarbeiten. Allerdings gab es in dieser Analyse eine wesentliche Lücke. Die Filterung nach Jahr wurde völlig übersehen, obwohl die Metadaten für jeden Artikel eindeutig das Veröffentlichungsdatum enthielten.
Um dieses Problem anzugehen, wiederholte ich die Anfrage und betonte diesmal die Wichtigkeit der Filterung für 2025, um sicherzustellen, dass sich das Modell nur auf Artikel aus diesem Jahr konzentriert.
output2 = rlm(
articles = articles,
question = '''What were the main AI trends of 2025 based on provided
articles? Pay attention to the content not only the titles.
Don't forget to filter by year, this information is present in
metadata for each article.'''
)Dieses Mal berücksichtigte das Modell das Jahr und führte eine anspruchsvollere Analyse durch, indem es reguläre Ausdrücke verwendete, um das Veröffentlichungsdatum für jeden Artikel zu extrahieren.
import re
from datetime import datetime
# Split articles by the separator "---" at the beginning of metadata blocks
# The pattern is: --- followed by metadata, followed by --- followed by content
article_blocks = re.split(r'n---n', articles)
print(f"Total article blocks found: {len(article_blocks)}")
print("n" + "="*80)
# Let's examine the structure - articles seem to start with "---ntitle:"
# Let me try a different approach - find all articles by their metadata pattern
article_pattern = r'---ntitle: "(.*?)"ndate: "(.*?)"ncategory: "(.*?)"nread_time: "(.*?)"nurl: "(.*?)"n---n(.*?)(?=n---ntitle:|$)'
matches = re.findall(article_pattern, articles, re.DOTALL)
print(f"Articles found with regex: {len(matches)}")
if len(matches) > 0:
print("nFirst article metadata:")
print(f" Title: {matches(0)(0)}")
print(f" Date: {matches(0)(1)}")
print(f" Category: {matches(0)(2)}")
print(f" Content preview (first 200 chars): {matches(0)(5)(:200)}")Anschließend wurden die Artikel nach Jahr gefiltert und 13 Artikel aus dem Jahr 2025 identifiziert.
# Parse articles and filter for 2025
articles_2025 = ()
for match in matches:
title, date_str, category, read_time, url, content = match
# Extract year from date string (format: "2025-10-24T12:00:00-05:00")
year = date_str.split('-')(0)
if year == "2025":
articles_2025.append({
'title': title,
'date': date_str,
'category': category,
'content': content.strip()
})
print(f"Total articles: {len(matches)}")
print(f"Articles from 2025: {len(articles_2025)}")
print("n" + "="*80)
print("2025 Articles:")
print("="*80)
for i, article in enumerate(articles_2025, 1):
print(f"n{i}. {article('title')}")
print(f" Date: {article('date')}")
print(f" Category: {article('category')}")
print(f" Content length: {len(article('content'))} chars")Anschließend wurden diese 13 Artikel mithilfe rekursiver Unteraufrufe analysiert und eine aktualisierte Liste von Trends erstellt. Diesmal wurde die Aufgabe korrekt erledigt. Wie bei vielen anderen Beispielen wird auch hier hervorgehoben, wie wichtig es ist, klare, explizite Fragen zu stellen und die Kriterien und Aktionen anzugeben, denen das Modell folgen soll.
Agentic AI and Multi-Agent Systems: Building autonomous AI agents capable of multi-step reasoning, tool use, planning, and reflection, often with multiple specialized agents collaborating on complex tasks
Code Agents: AI agents that execute tool calls using actual code (Python) instead of JSON-based tool calling, enabling dynamic function creation and achieving higher success rates with fewer steps
Model Context Protocol (MCP): Anthropic's standardization protocol for connecting AI applications to external tools and data sources, reducing integration complexity from M*N to M+N and enabling reusable, framework-agnostic components
Agent Communication Protocol (ACP): Emerging open protocol under the Linux Foundation for standardizing communication between AI agents via RESTful APIs, enabling interoperability across different frameworks
Reflection and Self-Refinement Patterns: LLMs reviewing and improving their own outputs through iterative feedback loops, including self-feedback, verbal reinforcement learning, and tool-interactive critiquing, achieving 10-30% accuracy improvements
Framework Ecosystem Proliferation: Multiple competing frameworks including LangGraph, smolagents, CrewAI, DSPy, and NeMo Agent Toolkit, with growing emphasis on interoperability and declarative configuration approaches
Production-Ready LLM Infrastructure: Moving beyond prototypes to address 'day 2' problems like API exposure, observability, monitoring, evaluation frameworks, and deployment at scale
Parameter-Efficient Fine-Tuning (PEFT) and LoRA: Techniques for customizing LLMs by updating only small subsets of parameters, enabling task-specific optimization while reducing computational costs and enabling on-premises deployment
Advanced Fine-Tuning with Memory Experts: Lamini's Mixture of Memory Experts (MoME) using ~1 million LoRA adapters for near-perfect factual accuracy (95%) with zero loss on specific information
Shift from Prompting to Programming Paradigm: Frameworks like DSPy treating LLM tasks as modular programming rather than manual prompt crafting, with structured signatures and reusable components
LLM Evaluation and Quality Assurance: Comprehensive evaluation frameworks (Evidently, DeepEval, MLFlow, LangSmith) for testing, monitoring, and ensuring reliability in production, especially for regulated industries
RAG (Retrieval-Augmented Generation): Providing relevant context and knowledge bases to enhance LLM precision and enable specialized capabilities in agents
Tool Use and Orchestration: AI systems dynamically selecting and executing tools from multiple sources, with standardized tool definitions and safety controls
YAML-Based Declarative Configuration: Defining LLM workflows, models, and agent behavior through configuration files rather than purely code-based implementations
Interpretable AI and Rule-Based Systems: Using decision trees, extracted rules, and transparent models as alternatives to black-box approaches for compliance, explainability, and rapid deployment in regulated industriesZusammenfassung
Es ist Zeit, die Dinge zusammenzufassen und über das Gelernte nachzudenken. In diesem Artikel haben wir RLM (Recursive Language Models) untersucht – eine neue Inferenzstrategie, die es LLMs ermöglicht, Kontexte zu verarbeiten, die bis zu zwei Größenordnungen größer als ihr Standardkontextfenster sind, und gleichzeitig das Problem der Kontextverrottung zu mildern.
Ich bin wirklich fasziniert von diesem Ansatz. Der Artikel schlägt eine einfache, aber elegante Methode zur Behandlung von Eingabeaufforderungen als Variablen in einer Python-Umgebung vor, die mich an mein bevorzugtes Agenten-Framework, Smolagents von HuggingFace, erinnert. Ich glaube, dass diese Methode besonders effizient ist, weil LLMs auf so viel Code trainiert wurden, dass sich das Programmieren für sie wie eine Muttersprache anfühlt. Die Verwendung von Code als Schnittstelle für Argumentation und Rekursion ist sowohl praktisch als auch leistungsstark.
Insgesamt bieten rekursive Sprachmodelle eine praktische und elegante Möglichkeit, die Grenzen der Kontextlänge zu überschreiten und LLMs in der Lage zu machen, komplexe, umfangreiche Aufgaben zu bewältigen. Klare Anweisungen und eine durchdachte Anleitung sind jedoch nach wie vor der Schlüssel zum Erzielen der besten Ergebnisse.
Vielen Dank fürs Lesen. Ich hoffe, dieser Artikel war aufschlussreich. Erinnern Sie sich an Einsteins Rat: „Wichtig ist, nicht mit dem Hinterfragen aufzuhören. Neugier hat ihre eigene Daseinsberechtigung.“ Möge Ihre Neugier Sie zu Ihrer nächsten großen Erkenntnis führen.
Referenz
Dieser Artikel basiert auf dem Artikel von Zhang et al., „Recursive Language Models“, veröffentlicht am 31. Dezember 2025.



{kind=link}